# 대시보드 템플릿
https://grafana.com/grafana/dashboards/

위 주소에서 원하는 형태의 대시보드 템플릿을 찾아보고, import 하여 사용합니다.
저는 여러가지 대시보드를 Import해서 각 템플릿에서 필요한 패널만 따로 Copy / Paste Panel 했습니다.

살짝 모자이크 처리를 했지만, 저는 위에 대시보드처럼
상단에 전체 서버를 Linux와 Window 계열로 나눠서 CPU / 메모리 / 디스크 정보에 대해 바로 확인 할 수 있도록 했습니다.
중간에는 주요 AP1호기 2호기로 구성했고,
제일 아래쪽에는 특정 서버 하나만 콤보박스로 선택해서 볼 수 있도록 구성했습니다.
아무리 좋은 템플릿을 찾더라도, 약간의 수정은 필요합니다.
우선 잘 반영되는 템플릿 여러개를 찾으시고,
각 템플릿에서 필요한 패널만 복붙으로 가져와서 입맛에 맞게 수정하시면 됩니다.
저는 주요 서버들이 약 20대 정도밖에 없지만, 클라우드쪽 관리자나 대형 서비스 관리자의 경우에는 수천대를 관리하기도 합니다. 서버 관리포인트에 중점이 어디인지 고민해보고, 다양한 템플릿들을 구글링해보면, 나만의 대시보드를 완성 할 수있습니다.
# Telegram Alert 연동

텔레그램 Bot Token, Chat Id를 입력하고 테스트를 누르면 해당 채팅방에 아래와 같은
테스트 메시지를 받아 볼 수 있습니다.

여기까지 했다면 이제 어떤상황에 알림을 받을지 설정하여 알림을 받으면 됩니다.
# CPU 알림 예시
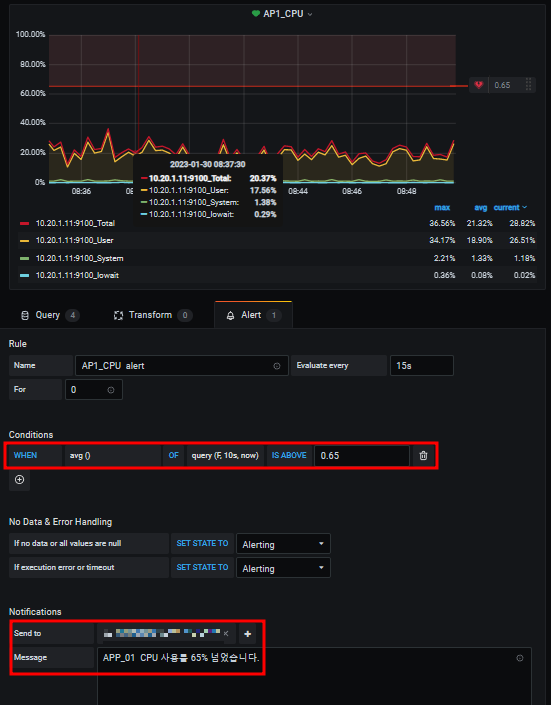
알림을 받고자 하는 패널 edit로 들어가서 Alert 탭으로 들어가서
어떤 상황(Conditions)에 알림을 받을지,
어떤 알림채널로(Send to) 알림을 받을지,
어떤메시지를 같이 보낼지 설정하고 저장합니다.

위에서 설정한 평균 CPU사용률이 65%가 넘어서 [Alerting] 메시지가 왔고,
사용률이 바로 65% 아래로 떨어지면서 [OK] 메시지가 왔습니다.
# 정리
저는 이미 대부분의 서버들에 대해 SNMP를 이용한 모니터링 솔루션을 통해 알림을 받고있기 때문에,
주요서버만 CPU, Ping, Volum, Memory 정도 알림을 걸어두고 사용하고있습니다.
그래서 주요 서버에 문제가 생기면, 두가지(Prometheus+Grafana, 모니터링솔루션) 경로로 알림을 받습니다.
Prometheus+Grafana 조합은 앞서 말했듯이, 데이터가 장기적으로 보관되지 않고, 대량의 서버들을 모니터링하거나 메인 모니터링 툴로 사용하기위해서는, Thanos, VictoriaMetrics 등의 연계활용이 필요합니다. 저 처럼 이미 모니터링 솔루션을 보유하고있으면서, 주요 서버에 대해 2차 모니터링(예비모니터링)으로 사용하시거나, 가볍고 간단하게 사용하기에 적합한것 같습니다.
저는 사무실에 대시보드가 없어서 처음 도입하게 되었고, 대시보드 뿐만 아니라,
기존 유료 모니터링 솔루션보다 좀 더 보기 편한 그래프로 Metrics 모니터링하는데 유용하게 사용하고있습니다.
장애 발생시, 해당 시간 전후로 시스템 자원이 어떻게 변했는지, 아니면 평소 시스템자원 점유수준이 어느정도가 정상인지,
어느정도 수준이상이면 점검이 필요한지 빠르게 파악가능했습니다.
'시스템&인프라 > 시스템모니터링' 카테고리의 다른 글
| [시스템 모니터링] Prometheus & Grafana - 03. Grafana 설치와 연동 (0) | 2023.01.26 |
|---|---|
| [시스템 모니터링] Prometheus & Grafana - 02. Prometheus 설치와 연동 (0) | 2023.01.13 |
| [시스템 모니터링] Prometheus & Grafana - 01. 소개와 설치 (0) | 2023.01.10 |